Mapas de coropletas: una guía para la clasificación de datos
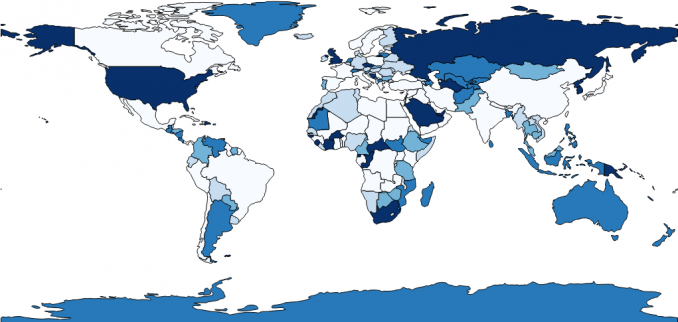
¿Qué son los mapas de coropletas?
Un mapa de coropletas utiliza diferentes sombras y colores basados en datos cuantitativos.
Pero el problema para los mapas choropleth es: Hay tan muchas maneras de clasificar los datos.
Por ejemplo, hay intervalos iguales , cuantil , rupturas naturales y rupturas bonitas.
Pero, ¿cuál es la diferencia entre cada uno de ellos?
Hoy, aprenderá a elegir la mejor manera de clasificar sus datos en mapas de coropletas en nuestra guía de clasificación de datos .
Elija su número de clases
Primero, debe agregar datos basados en varias clases. Cuando tienes más clases, obtienes más variación, lo que a veces hace que sea más difícil separar el sombreado. Si desea probar diferentes tonos , ColorBrewer tiene una herramienta para consejos de color.
Por ejemplo, aquí hay 10 clases :

Mientras que menos clases proporciona menos separación entre clases, como las 5 clases a continuación.
Después de todo, la cantidad de clases que decida realmente depende del propósito de su mapa.
Seleccione su método de clasificación de datos
En segundo lugar, tendrá que decidir cómo clasificar sus datos. Para decirlo de otra manera, la clasificación de datos organiza sus datos con límites para separar clases. Puede separar sus clases con un modo de intervalo igual:
Alternativamente, puede seleccionar un tipo de clasificador de cuantiles donde organice los datos de manera diferente (más sobre esto a continuación)
Cada técnica de clasificación de datos produce mapas de coropletas únicos . Pero todos pintan una historia diferente para el lector de mapas. Lo único que debe darse cuenta es que está utilizando los mismos datos en cada mapa de coropletas, pero lo que realmente está cambiando es cómo clasifica los datos .
Crear un mapa de coropletas
Lo más importante de lo que debes darte cuenta es que para cada uno de estos mapas de coropletas que creamos, usamos los mismos datos . Lo que está cambiando es cómo clasificamos los datos.
En este ejemplo, contamos el número de letras en los nombres de los países. Por ejemplo:
- Malí, Cuba y Perú y otros son países de cuatro letras .
- Mientras que Bosnia y Herzegovina tiene 22 caracteres.
Si traza de 4 a 22 caracteres, tendrá muchos colores.
Por ejemplo, los países de cuatro letras son los tonos más claros de verde. A medida que aumenta el número de letras, el sombreado se vuelve más oscuro.
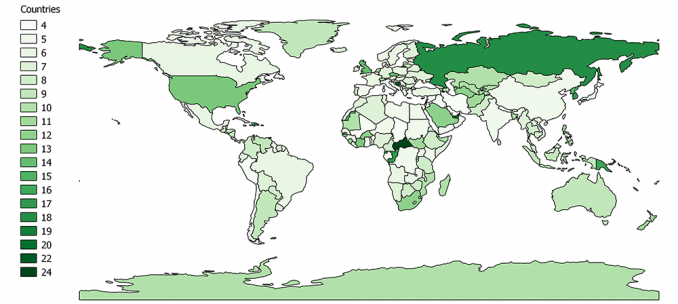
¿Qué país pertenece a qué grupo? Es difícil de contar.
Por eso utilizamos la clasificación de datos. Cuando agrupamos por clases, hay menos sombreado y agregamos los datos por grupo.
En última instancia, la pregunta es ¿cómo definimos esos límites de clase o contenedores? En otras palabras, ¿cómo clasificamos los datos en grupos?
Primero, intentemos dividir las clases en agrupaciones espaciadas uniformemente como intervalos iguales a continuación y veamos qué sucede.
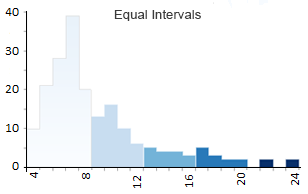
Clasificación de datos a intervalos iguales
La clasificación de intervalo igual es corta y seca. Todo lo que realmente hace es dividir las clases en grupos iguales .
- Clase 1 : 4 – 8 (113 países tienen cuatro, cinco, seis, siete u ocho letras)
- Clase 2 : 8 – 12 (41)
- Clase 3:12 – 16 (12)
- Clase 4:16 – 20 (8)
- Clase 5:20 – 24 (2)
El número mínimo de caracteres de un país es 4 como Perú. El número máximo de caracteres es 24 , que es República Centroafricana. Cuando traza cada país y su número de caracteres en un mapa, se ve así (los corchetes indican el recuento):
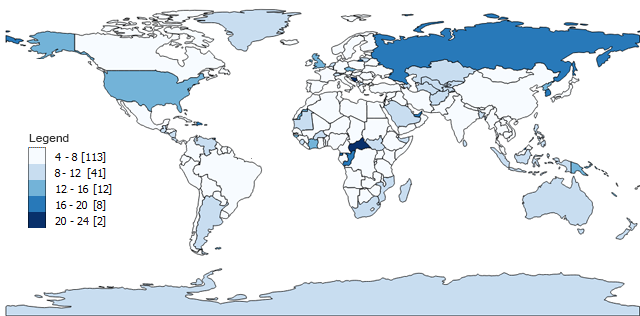
La clasificación de datos de intervalo igual resta el valor máximo del valor mínimo ( 24-4 = 20 ). En nuestro ejemplo, generamos 5 clases, pero la cantidad de clases depende completamente de usted. Luego, divide 20 entre 5 y obtiene un intervalo ( 20/5 = 4 ).
Casi siempre, los mapas de coropletas de intervalos iguales dan como resultado un recuento desigual de países por clase . Por ejemplo, la clase 1 tiene 113 países de 176 países con cuatro, cinco, seis y siete letras.
Sin embargo, solo 2 países tienen más de 20 letras. Como resultado, este mapa muestra más colores sombreados claros en comparación con solo 2 con sombreado oscuro.
Pero, ¿qué sucede si desea que el recuento de países en cada clase sea casi igual? Ahí es cuando debes usar un mapa de cuantiles.
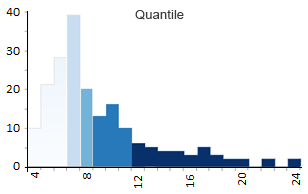
Clasificación de cuantiles (recuento igual)
El mapa de cuantiles intenta agrupar el mismo recuento de características en cada una de las 5 clases. En otras palabras, los mapas de cuantiles intentan organizar grupos para que tengan la misma cantidad . Como resultado, el sombreado se verá igualmente distribuido en tipos de mapas de cuantiles.
- Clase 1 : 4 – 6 (56 países tienen nombres de 4, 5 o 6 letras)
- Clase 2 : 6 – 7 (38)
- Clase 3 : 7 – 8 (19)
- Clase 4 : 9 – 11 (36)
- Clase 5:12 – 24 (27)
Los mapas de cuantiles toman el número de características (176 países en nuestro caso). Luego, divide el total por el número de clases para obtener el promedio ( 176/5 = 35,2 ). Finalmente, los mapas de cuantiles cuentan la cantidad en cada grupo y los ordenan lo más cerca posible del promedio.
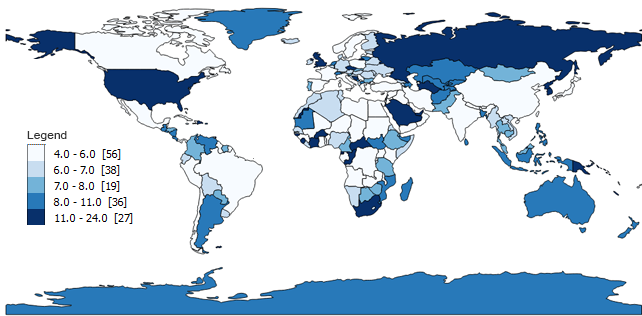
Puede ver cómo el recuento de cada clase se ve muy similar y se acerca a 35,2 . Para cada clase, no hay demasiados ni muy pocos para el recuento.
A pesar del estilo equilibrado de los mapas de coropletas cuantílicos, también pueden ser engañosos. Son engañosos porque las personas tienden a mirar uno de los tonos y agruparlo en la misma categoría. Por ejemplo, un país de 12 letras tiene el mismo sombreado oscuro que un país de 24 letras … ¿y dónde está la justicia en eso?
Clasificación de rupturas naturales (Jenks)
Lo primero que debe recordar acerca de la clasificación Natural Breaks (Jenks) es que es un método de optimización para mapas de coropletas. En resumen, organiza cada agrupación para que haya menos variación en cada clase o sombreado.
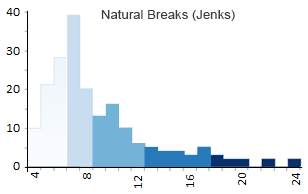
- Clase 1 : 4 – 6 (56)
- Clase 2 : 6 – 8 (57)
- Clase 3 : 8 – 12 (41)
- Clase 4:12 – 18 (18)
- Clase 5:18 – 24 (4)
Natural Breaks (Jenks) adopta un enfoque iterativo al comparar la suma de las desviaciones cuadradas entre clases con la media de la matriz. Luego, el algoritmo utiliza un ajuste de bondad de varianza con 1 como ajuste perfecto y 0 como ajuste deficiente.
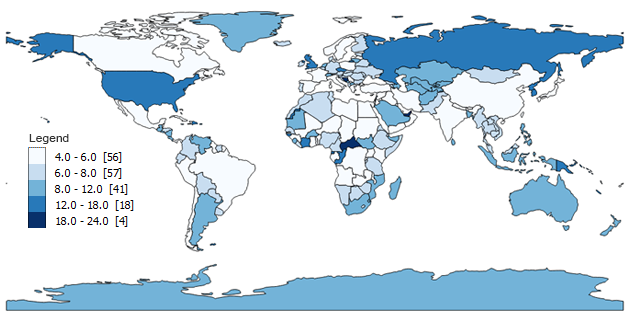
El fundador del método de clasificación de datos Natural Breaks fue un cartógrafo llamado George Frederick Jenks. Se especializó en monitorear los movimientos oculares de las personas cuando miran un mapa. Y los resultados de este mapa también se vieron muy bien.
Puede ver cómo este método de clasificación de datos minimiza la variación en cada grupo . Como tenemos muchos nombres de países más cortos, encuentra rangos de clases adecuados. Pero aún se las arregla para agrupar valores atípicos con nombres de países más largos en una clase propia.
Clasificación de desviación estándar
La desviación estándar es un tipo de mapa de técnica estadística que se basa en cuánto difieren los datos de la media. Mide la media y la desviación estándar de sus datos. Luego, cada desviación estándar se convierte en una clase en sus mapas de coropletas.
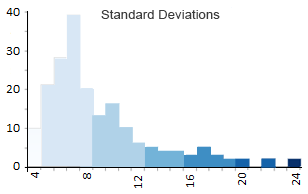
En nuestro caso, el número medio de caracteres es de aproximadamente 8,5 con una desviación estándar de 3,7 caracteres. Como resultado, todos los países con 5 a 8 caracteres se ubicarán en el grupo de desviación estándar de 0 a -1. Asimismo, los países con 9 a 12 letras se agrupan en un rango de desviación estándar de 0 a 1 de la siguiente manera:
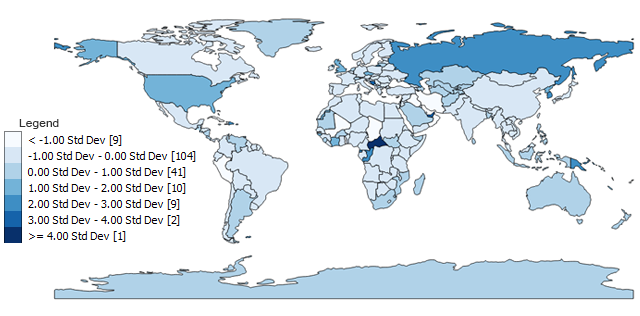
- Clase 1 : <-1 σ (9)
- Clase 2 : -1 a 0 σ (104)
- Clase 3 : 0 a 1 σ (41)
- Clase 4 : 1 a 2 σ (10)
- Clase 5 : 2 a 3 σ (9)
- Clase 6 : 3 a 4 σ (2)
- Clase 7 :> = 4 σ (1)
Las categorías en bruto como salida necesitan un poco de aclaración para el lector. Cual es el promedio? ¿Cuál es el rango para cada desviación estándar?
A pesar de estas inconsistencias, los tipos de mapas de desviación estándar pueden ser uno de los más apropiados debido a su origen estadístico . Todos los países de 4 letras tienen desviaciones estándar <-1. Los países con 5 a 8 letras tienen una desviación estándar de -1 a 0. El único país de 24 letras tiene> 4 desviaciones estándar debido a su desviación extrema de la media de 8.5.
Clasificación de Pretty Breaks
Si desea números redondos en sus rangos, debe elegir descansos bonitos. Todo lo que hace la clasificación de “bonitos descansos” es redondear cada punto de quiebre hacia arriba o hacia abajo. Entonces, en lugar de tener un punto de ruptura como 599.364, se convertirá en 600,000 con bonitas rupturas.
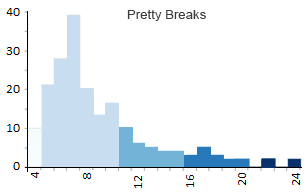
Es un poco difícil ver qué tan redondeados están los números (está agrupando por 5) en este ejemplo porque todos los ejemplos anteriores también producen números redondos. Pero cuando tiene números grandes como estimaciones de población (ver más abajo), generará algunas rupturas muy bonitas.
- Clase 1 : 4 – 5 (29)
- Clase 2 : 5 – 10 (111)
- Clase 3:10 – 15 (24)
- Clase 4:15 – 20 (10)
- Clase 5:20 – 24 (2)
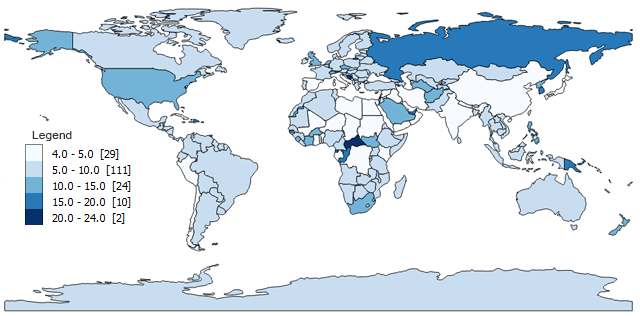
Como resultado de hacer números redondeados, los descansos bonitos también serán muy exigentes con la cantidad de clases que decidas.
Así es como se comparan las estimaciones de población cuando observa todas las técnicas de clasificación de datos:




Pruébelo usted mismo
Los mapas de coropletas utilizan diferentes sombreados y colores para mostrar la cantidad o el valor en áreas definidas.
A menudo es el caso, el creador de mapas utiliza un tipo de clasificación de datos para producir su propio mapa de coropletas único . Cada método de clasificación de datos impacta al lector de manera diferente.
Hay varias formas de clasificar los datos en un SIG. Hemos resumido sus diferencias con diferentes ejemplos de mapas de coropletas. Utilice esta guía para clasificar prácticamente cualquier cosa, como tasas de criminalidad, niveles de educación y política.
¿Cuál es su método de clasificación de datos favorito? Haznos saber con un comentario debajo.
Traducido de https://gisgeography.com/choropleth-maps-data-classification/

